 |
shedevr.org.ru
Группа перевода приставочных игр "ШЕДЕВР"
|
| Предыдущая тема :: Следующая тема |
| Автор |
Сообщение |
Axel
Советник

Зарегистрирован: 14.11.2003
Сообщения: 680
|
 Добавлено: Чт Фев 02, 2006 7:47 pm Заголовок сообщения: Пояснения к ПокеПеревод версии 2 Добавлено: Чт Фев 02, 2006 7:47 pm Заголовок сообщения: Пояснения к ПокеПеревод версии 2 |
 |
|
В этой теме я начну публиковать разные тексты,
которые писались по поводу и без повода, в процессе разработки
второй версии ПокеПеревода...
(иногда может показаться, что эти тексты выглядят как раговор,
в смысле "вопросы/ответы", так и есть это некоторые выдержки из
моей почтовой переписки с членами группы...)
сюрприз: 
http://www.shedevr.org.ru/utils/Files/fullPP2v038.zip
терминология
SBCS - Single Byte Character Set (однобайтовая кодовая страница), где один символ
всегда кодируется кодом от 0 до 255 (0-FF), характерные представители
таких кодировок windows-1251, cp866
DBCS - Double Byte Character Set (двухбайтовая кодировка), где каждый символ
всегда кодируется двумя байтами и может принимать значения от -32767 до +65535
(0000-FFFF), характерный представитель cp932 (японская кодовая страница в MS Windows)
DUMP - некий текстовый файл, где не описанные в таблице символы укодированы (encoded)
как "<$"+hh+">", где hh это hex код того самого неописанного символа, остальные
символы кодируются просто "буквами". По сути это просто "поток" байт для
ставления в файл (ROM). Этот файл как правило не содержит информации откуда,
что вынуто. Единственная цель дампа представить в тестовом виде некий кусок
двоичного файла.
пример дампа:
-------начало файла
<$08><$07>PRACTICE++NEW GAME++OPTIONS++PASSWORD*<$06><$02>
-------конец файла
SCRIPT - текстовый файл который содержит "красиво" оформленный текст вынутый из
файла (ROM'a), этот файл как правило не содержит информации откуда, что вынуто
но часто содержит информацию о том, в каком порядке следуют фразы и кто
их произносит, а так же фразы могут быть пронумерованы для дальнейшей
работы с ними переводчиков...(или программы вставляющей эти куски в файл(ROM))
script как правило не содержит "укодированных" последовательностей
типа "<$F0><$BB>" или содержит их в минимальном объеме.
пример скрипта:
-------начало файла
Crew:Captain Cecil,
we are about to arrive!
Cecil:Good.{END}
Crew:Why are we robbing
crystals from innocent
people?
Crew:That's our duty.
Crew:Do we really have to
keep doing this?{END}
Crew:Captain!
Crew:We can't stand doing
this anymore!
-------конец файла
Как правило, при переводе ромов (не важно делаем ли мы dump'ы или script'ы)
необходимо хранить кучу дополнительной информации (например откуда, что вынули),
для этого в тех программах, что я видел используется понятие "dump-закладки"
(dump-bookmarks), которые чаще дописываюся прямо в файл с таблицей. Выглядят
эти закладки примерно следующим образом:
-------начало файла таблицы
41=A
42=B
43=C
...
-------начало закладок
[81600h-8A600h]Dialogue Block 1
[84600h-86600h]Dialogue Block 2
[87650h-8D650h]Dialogue Block 3
{80600h-FF4dump1.txt}Dialogue Block 1
{84600h-FF4dump2.txt}Dialogue Block 2
{87650h-FF4dump3.txt}Dialogue Block 3
-------конец файла таблицы
...причем в этом случае каждый дамп(script) лежит в отдельном файле...
Целью первой версии ПокеПеревода было сделать так, чтобы автоматически
дампились определенные части рома (там где есть "текст"), причем поскольку
хорошего алгоритма для отличения "текста" от "нетекста" просто нет (кроме
искусственного интелекта с кучей словарей и пр.), то таких минидампов
набегало 10-20 тысяч!, что естественно нереально для файловой системы,
поэтому откуда, что вынималось складывалось прямо рядом с тем, что вынималось...
так появился термин "файл перевода".
Вторым достоинством ПокеПеревода v1.x было то, что он не позволял вылезти
за размер того куска, который мы вынули из файла (ROM'а), приклад
просто полагал, что то, что загружено это и есть оригинальная длинна...
Ввиду простоты выбранных алгоритмов и формата так называемых файлов перевода
вылезли различные ограничения:
- таблица только в SBCS (однобайтовая)
- "символ" отделяющий один минидамп от другого только "конец строки" crlf (0D0Ah)
- в начале каждой строки число, которое одновременно и идентификатор минидампа
и адрес в файле(ROM'е) начиная откуда он сделан и адрес в файле(ROM'е) куда
его будут вставлять и в последствии на основании этого-же числа генерировался
образ поинтера (для GBA)
- для отделения "игровых строк" (то, как строки выводятся на экран самой игрой)
приходилось использовать спец символы (из тех же самых 32-255), ниже пример файла
перевода, где в качестве такого символа используется знак "=" (равно)
-------начало файла перевода
183637 УДАРИТЬ ЛАПАМИ =ИЛИ ХВОСТОМ.
1875760 УДАР КАРАТЕ
183669 ВЕЛИК ШАНС КРИТИ-=ЧЕСКОГО УДАРА.
1875772 ДВА ШЛЕПКА
183702 ШЛЕПНУТЬ 2-5 РАЗ= ЗА ХОД.
1875783 УДАР КОМЕТЫ
183730 УДАРИТЬ 2-5 РАЗ= ЗА ХОД.
1875795 МЕГА УДАР
183760 МОЩНЫЙ УДАР И =МНОГО ПОВРЕЖДЕНИЙ.
-------конец файла перевода
...и все это было очень неудобно, потому, что строка текста удлиннялась и нормально
редактировать ее становилось уже проблематично...
Основной идеей ПокеПеревода версии 2.х являлось снять эти ограничения, для этого
я придумал хитрый ход, который обеспечил совместимость с файлами перевода
из прошлой версии, но дал возможность оформить эти минидампы гораздо наглядее...
Для начала я придумал, что в INI файле можно назначить какой последовательностью
символов мы отличим один минидамп от другого, и как мы отличим всякие сопровождающие
этот минидамп параметры, типа откуда вынули, куда класть, какой поинтер, оригинальная
длинна минидампа, комментарии и т.д. и т.п. Причем, хотелось, чтобы и порядок и
количество этих пераметров можно было менять (и наращивать...  ) не переписывая ) не переписывая
процедуру загрузки и сохранения файла с этими минидампами и их атрибутами...
-------начало куска INI файла pokeper2.ini
DialogDelimiterStr=<$VBCRLF>§<$VBCRLF> 'строка символов для разделения диалогов в вынутом тексте
DialogAttrSeparator=, 'строка символов - разделитель атрибутов диалога МЕЖДУ СОБОЙ
DialogAttrDelimStr=<$VBCRLF>¶<$VBCRLF> 'строка символов - разделитель атрибутов диалога от текста диалога
TrDialogFileFormat=dlgID,ExtractedFromAddr,OldDlgSize,NewDlgSize,DoPointerChange,NewDlgAddr,OldPtrHEX,
NewPtrHEX,PtrsAddrListFile,dlgComments,dlgText 'список названий атрибутов диалога!!! порядок ВАЖЕН, последние 2 обязательны
-------конец куска INI файла pokeper2.ini
Тут мы подходим к еще одному термину, без которого мне не обойтись - DIALOG
(или "Файл диалогов"). Фактически Диалог - это некий дамп из ROM'а плюс
его свойства, такие как откуда вынули, куда сунем и т.д. Нескольлко диалогов
объединенные в один файл - это Файл диалогов. Причем тут мы действительно можем
приравнять "диалоги игровые" к диалогам вынимаемым и хранимым в файле диалогов...
-------начало файла диалогов
497026,79582,,,,,,,,
¶
ЕСЛИ ТВОЕМУ<$cr2>
<$POKE>МОНУ БУДЕТ<$newscreen>
НУЖНА ПОМОЩЬ<$cr2>
ИСПОЛЬЗУЙ ЭТУ<$lf>
МАШИНУ<$newscreen>
ЕСЛИ НАДО,ЗАХОДИ<$cr2>
В ЛЮБОЕ ВРЕМЯ
§
497166,7960E
¶
МИСТЕР <$POKE>МОН<$cr2>
ХОДИТ ПО СВЕТУ<$newscreen>
И СОБИРАЕТ РАЗНЫЕ<$cr2>
РЕДКОСТИ,<$newscreen>
ЖАЛЬ ТОЛЬКО,ОНИ<$cr2>
ЧАЩЕ БЕСПОЛЕЗНЫЕ.
§
-------конец файла диалогов
...причем куча запятых в конце строки атрибутов диалога, вообще говоря не обязательна,
просто при загрузке диалогов не описанные параметры будут нулевые (или пустые),
с другой строны если позднее кто-то напишет свою программу для работы с файлами
диалогов и придумает свои собственные параметры (и поставит больше запятых),
то ПокеПеревод просто будет ситать их частью комментариев показывая и работая с
теми, что он знает и понимает...(естественно он не потеряет, те, что ему не известны )
Как ты наверное заметил, теперь есть возможность в правой части таблицы перекодировки
писать более одного символа, !!!однако если хочешь правильно возвращать текст в ROM,
в начале нужно писать "<$", а в конце ">", если возвращать вынутый текст не требуется
(или для этого будет использоваться другая программа), то можно этого и не делать и
использовать таблицу типа такой:
--------начало таблицы
80=0
9A= this
5F=ed
30= t
0400=Cecil
--------конец таблицы
Да!, правильно, теперь в левой части таблицы можно писать число от 00h до FFFFh,
что дает нам возможность описать на пример ВСЕ японские иероглифы...
Однако тут есть один подводный камень, дело в том, КАК программа будет
анализировать поток байт их входного ROM'а, надо ли откусывать по одному байту
или байты нужно анализировать ПАРАМИ? Поэтому я придумал "Тип таблицы" в настоящее
время он может быть SBCS,DBCS или SBCS2. Для явного указания типа таблицы в файле
с таблицей перекодировки можно в отдельной строке написать "TrTableType=SBCS2"
SBCS - откусываем по одному байту и ищем символ с его кодом в таблице
DBCS - откусываем по два байта и ищем символ с таким кодом в таблице
SBCS2 - откусываем по одному байту и ищем символ с его кодом в таблице
если однобайтовый код не описан(не найден), то ДОкусываем еще один байт
ищем уже двухбайтовый код в таблице...
На самом деле, тип таблицы не важен для алгоритма вытаскивания текста,
но он важен для просмотрщика ROM'ов и он важен при подсчете длинны
вынутого диалога в "символах", а не байтах...
Ну и напоследок, таблица перекодировки и то, что ПП2 генерирует (файлы диалогов)
могут по желанию сохраняться/вставляться в unicode, что
очень удобно... поскольку мы не ограничены набором "печатных" символов,
а с помощью charmap.exe можем выбрать те, что душе угодно...
Ещё одна возможность версии 2 - Х-редактор игровых текстов...
...я задумал сделать его таким, чтобы
можно было редактировать текст с пропорциональными шрифтами
и сразу видеть влезает он в окошко игры или нет...для этого
я придумал задействовать еще три файла:
1. с шириной символов в формате код=ширина
2. с .bmp со шрифтом из игры
3. с фоновой картинкой для создания эффекта присутствия :-)
Вкусности в версии ПокеПеревода 2:
1. файл таблиц и вынимаемый/вставляемый файлы при необходимости
могут быть в формате Unicode, это позволяет в частности
использовать ЛЮБЫЕ символы для описания кодов, т.е. в правой части таблицы
мы можем написать хоть русские буквы, хоть японские иероглифы
(для этого правда нам понадобится использовать нечто типа утилиты charmap.exe,
поскольку "набить" на клавиатуре мы иероглифы не сможем...)
причем файл в формате юникод нормально редактируется скажем notepad.exe
(правда Windows для этого должна быть Win2000/XP/2003, но НЕ Win95/98/Me)
для того чтобы создать(сохранить файл) в notepad в формате unicode
нужно просто нажать "save as" и выбрать тип кодировки(encoding) = Unicode
(для нормального ОТОБРАЖЕНИЯ символов можно выбирать шрифты типа MS Mincho,
он появится если на пример добавить японскую locale...)
утилита PokePerevod v2 сама догадается о формате файла (ANSI или Unicode)
и нормально его прочитает...
!!! НО не забудь проверить, наличие галочки в меню "Options" -->
"Писать файлы в Unicode", иначе после сохранения файл станет ANSI...
(впрочем, всегда создается .BAK файл... )
2. в правой части таблицы (ПОСЛЕ знака "равно") перекодировки можно писать
более одного символа, !!!однако если хочешь _правильно_ возвращать
текст в ROM, в начале нужно писать "<$", а в конце ">"
...использование такого подхода, позволит существенно упростить работу
если некоторые слова в скриптах игры описываются по "словарному" методу...
(такое бывает, например, с именами героев или названиями предметов)
пример:
--------
01=A
02=B
10=<$hammer>
18=<$this>
> 1. Символ переноса
> 2. Символ обновления окна
> 3. Символ скроллинга
Ты прав...
3. В скриптах часто используются спец. коды для управления выводом текста
на экран, причем таких спец. кодов может быть и больше...
и часто хочется, чтобы "перенос на другую строку" и в вынимаемом тексте
выглядел как "перенос на другую строку" (для PC это пара символов 0x0D0A)
поэтому, в ПП2 я пришел к тому, чтобы сделать "crlf" обычным символом
т.е. НЕ использовать его как разделитель "строк перевода" в "файле перевода",
для этого в INI файле можно задать КАК утилита отличит один диалог от другого...
кусок pp2.ini
-------------
DialogDelimiterStr=<$VBCRLF>§<$VBCRLF> 'строка символов для разделения диалогов в вынутом тексте
DialogAttrSeparator=, 'строка символов - разделитель атрибутов диалога МЕЖДУ СОБОЙ
DialogAttrDelimStr=<$VBCRLF>¶<$VBCRLF> 'строка символов - разделитель атрибутов диалога от текста диалога
таким образом, в данном случае, один диалг от другого отделяется комбинацией
"перенос на след строку"+некий символ+"перенос на след строку"
... правильно, строка "<$VBCRLF>" в вынутом тексте превращается в перенос на след строку
!!! эту штуку писать ОБЯЗАТЕЛЬНО заглавными буквами !!!
иначе это будет считаться "обычным символом"
значит, теперь мы можем "игровой перенос на след. строку" описать в таблице как
0A=<$lf><$VBCRLF>
сочетание "<$lf>" нужно просто, для наглядности... в вынутом скрипте это
будет выгдялеть как:
кусок скрипта ПП2
-----------------
4866378,4A414A,,,,4A414A,,,,
¶
7Oh well…<$lf1>
What happens, happens.<$scroll>
§
4866412,4A416C,,,,4A416C,,,,
¶
You need to learn<$lf1>
from your mistakes.<$more>
About that favor…<$lf1>
I need you to find<$lf1>
<$Bijou> for me.<$scroll>
But first, we should go<$lf1>
over some Ham–Chats.<$lf1>
§
согласись, выглядит более читаемо, чем в ПП1 :)
...куча запятых в конце строки атрибутов диалога, вообще говоря не обязательна,
просто при загрузке диалогов не описанные параметры будут нулевые (или пустые)
тут нужно пояснить, что такое "атрибуты диалога" - это "строка перевода" в
терминологии ПП1 + дополнительные вещи, типа адрес КУДА возвращать текст,
нужно ли менять поинтер, длинна оригинальной (вынутой) "строки" и т.п. и т.д.
Несколько диалогов, объединенные в один файл это "Файл диалогов".
Причем тут мы действительно можем приравнять "диалоги игровые" к
диалогам вынимаемым и хранимым в файле диалогов...
еще один пример:
-------начало файла диалогов
497026,79582,,,,,,,,
¶
ЕСЛИ ТВОЕМУ<$cr2>
<$POKE>МОНУ БУДЕТ<$newscreen>
НУЖНА ПОМОЩЬ<$cr2>
ИСПОЛЬЗУЙ ЭТУ<$lf>
МАШИНУ<$newscreen>
ЕСЛИ НАДО,ЗАХОДИ<$cr2>
В ЛЮБОЕ ВРЕМЯ
§
497166,7960E
¶
МИСТЕР <$POKE>МОН<$cr2>
ХОДИТ ПО СВЕТУ<$newscreen>
И СОБИРАЕТ РАЗНЫЕ<$cr2>
РЕДКОСТИ,<$newscreen>
ЖАЛЬ ТОЛЬКО,ОНИ<$cr2>
ЧАЩЕ БЕСПОЛЕЗНЫЕ.
§
-------конец файла диалогов
в файле таблицы у меня написано следующее:
-------------------------кусок таблицы
1F=<$cr0><$VBCRLF>
4E=<$cr1><$VBCRLF>
4F=<$cr2><$VBCRLF>
51=<$newscreen><$VBCRLF>
54=<$POKE>
55=<$lf><$VBCRLF>
9D=<$ай>
9E=<$кс>
9F=<$дж>
A0=a
A1=b
A2=c
DA=<$ПО>
DB=<$КЕ>
DC=<$МО>
DD=<$ТЬ>
DE=<$НЕ>
E1=<$PK>
E2=<$MN>
F7=1
F8=2
F9=3
-------------------------кусок таблицы
вобщем, думаю, общий смысл нововведений тебе уже становится понятнее...
4. есть еще штука под названием "Постпроцессор", но про него я напишу позже...
_________________
Всех их вместе переведём!
Последний раз редактировалось: Axel (Чт Мар 02, 2006 1:20 am), всего редактировалось 2 раз(а) |
|
| Вернуться к началу |
|
 |
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Вт Фев 07, 2006 2:37 pm Заголовок сообщения: |
|
|
Алгоритм вынимания текста из ROM'а не всегда позволяет правильно угадать так называемое "начало" строки. Особенно в тех играх, где в скриптах используются разные "особенности", (например ссылки на словарь со списком атак или имен героев или еще чего-то в том же духе), эти ссылки обычно кодируются прямо в скрипте и могут быть многобайтовыми или однобайтовыми, в зависимости от изобретательности разработчиков...
Теперь представь ситуацию, когда в начале диалога должно быть написано имя героя (из словаря), причем закодировано оно, скажем парой байт... С точки зрения Покеперевода (и если у нас нет таких кодов байт в таблице) эта пара байт в начале диалога будет пропущена, поскольку она "непечатная"... это значит, что вынутый кусок "печатного" текста будет иметь такой "поинтер", которого не существует... ведь игра-то ссылается на адрес, который на два байта РАНЬШЕ, чем то место, откуда думает покеперевод... В общем, получится так, что если мы захотим вставить этот текст в другое место рома и исправить указатель (внутре-игровой поинтер), на нашу строку, то ничего у нас не выйдет...
Для выхода из такой ситуации, задумано следующее:
В ПП2 есть возможность пробежаться по ROM'у и поискать все сочетания байтиков, которые, в принципе могут быть указателями (поинтерами) и вынуть все адреса таких подозрительных мест в файл отчета, для последующего глубокого вглядывания.
Пример файла протокола, по поиску поинтеров:
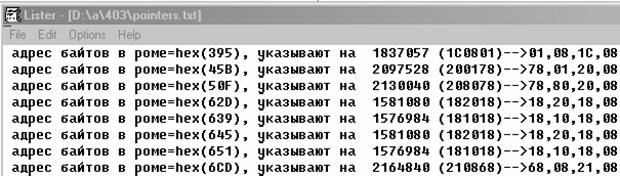
Для пущего удобства можно указать границы КУДА МОГУТ смотреть найденные указатели, таким образом мы можем отсечь довольно много мусора... Мы ведь знаем где в роме лежат наши "печатные" строки... (еще раз - это НЕ то место ГДЕ наши поинтеры, а то КУДА они смотрят!)
Далее, мне не замедлила прийти идея о следующем - сделать вынималку текста по тем самым поинтерам (которые МОГУТ быть поинтерами, а могут и не быть), указанным в том файле протокола из предыдущего пункта... Такая функция была сделана...
Поскольку кодов с "непечатными" символами у нас в таблице может быть не описано, то получившаяся функция не является, строго говоря, выниманием текста, и была названа "Дамп текста по указателям"...
В процессе тестирования всего этого хозяйства выяснилось, что таких похожих на поинтеры байтиков в роме может найти доооофига ~50-200 тысяч! И обрабатывать их в памяти довольно долго, поэтому я решил использовать временный файл... сначала туда сваливаются указатели из файла протокола поиска поинтеров, потом оттуда они вычитываются, сортируются и в итоге в том временном файле оказываются отсортированные указатели, причем только в единственном числе... (еще раз - во временном файле лежат отсортированные УКАЗАТЕЛИ, а не их адреса...) Лежат они в десятичном виде, т.е. достаточно взять оттуда циферку и прыгнуть по этому смещению в роме и мы попадем на предполагаемое начало диалога.
Этот временный файл я не стираю... отставляя возможность его укоротить (ручками в notepad) и прогнать дампер еще раз... еще много, много раз ;)
После того как программа разобралась с указателями, она, используя таблицу, начинает вынимать текст, !!! если код байта из рома НЕ известен в таблице, он енкодится в виде <$xx>, где xx - шестнадцатеричный код того байта...
Еще один момент - поскольку, укодируя все "непечатные" символы, я теряю возможность отличить где кончается один блок данных скрипта и начинается другой, я решил просто делать дамп от одного поинтера до другого... НО для последнего поинтера (указанного в том временном файле) этот трюк не годится и решил я просто брать первые 32000 байт... и в начале такого "обрезанного" диалога я пишу слово "Trimmed...!!!..."
То есть, если ты вначале диалога встретишь слова "Trimmed...!!!...", это означает, что тут не всё , а только первые 32 килобайта. Можно конечно отрезать руками "Trimmed...!!!..." (именно так с тремя точками и восклицательными знаками...), но лучше просто его удалить или если там есть что полезное, тогда надо во временный файл (там где лежат отсортированные поинтеры) дописать в конец еще адресок... тогда последним будет уже другой диалог... :)
идем дальше...
Поскольку не все то поинтер, что на него похоже, то получается, что файл диалогов может выглядеть так:
| Код: |
1310343,13FE87
<$12> [••_••_••_ Are you saying\
you are the one?+
You say that you are\
the @child@\
for the mission!? ^^+
••All right then ^^ prove\
it to me!!<$00>
§
1310481,13FF11
<$12> [Go ahead•• <$Chaos>!+
Let me see you open the\
gate •• destined child+
^^ and•• that is when you\
will know the strength\
of God!!<$00>
§
1310606,13FF8E
[•• We're set! ^\
Let's go!<$00>
§
1310633,13FFA9
<$06><$01>\
[Elder! Please give us\
work!+
We're full<$F0>fledged\
workers now!<$00>
§
1310699,13FFEB <-----------------------
Elder\
[I know, I know\
H
§
1310723,140003 <-----------------------
e
§
1310724,140004 <-----------------------
re's
§
1310728,140008 <-----------------------
a job for you ••<$00>
§
1310746,14001A
<$06><$01>\
[Hum, let me see••?+
What! <$ED>Find a pet<$EE>!?<$00>
§
1310792,140048
Elder\
[•• You don't want to\
do it?<$00>
§
|
Обрати внимание на те места, что я отметил стрелочками... Тут, по всей видимости получилось так, что в роме нашлись "поддельные" поинтеры, ссылающиеся на середину текста игрового диалога поэтому фраза "Elder\[I know, I know\Here's a job for you ••" развалилась на несколько покепереводных диалогов... НО поскольку наш интеллект мощнее машинного, такую фигню мы можем убрать... Для этого в том временном файле нужно поискать поинтеры, которые я отметил и... удалить из него такие строки .
А потом прогнать дампер еще разок, перепрыгнув через шаг по разбору файла протокола поиска поинтеров и сортировки...
внимательно читай ЧТО спрашивает дампер...
Или просто руками "объединить" диалоги в notepad, удалив всё лишнее, чтобы получилось:
| Код: |
1310699,13FFEB
Elder\
[I know, I know\
Here's a job for you ••<$00>
§
|
В итоге мы получаем диалоги, которые мы можем двигать, поскольку мы на 99% уверены, что мы точно знаем их начала и соответственно можем вычислить внутри-игровой указатель и поменять старый указатель на новый...
Теперь, несколько слов по поводу ограничения количества исправлений указателей при вставке текста диалогов в другое место рома.
Вариант 1.
Когда мы ЗНАЕМ что за поинтеры и где в роме именно поинтеры а где просто похожие комбинации байт.
Для этого нужно по файлу протокола и методом тыка и глубокого вглядывания сделать файл со списком АДРЕСОВ в роме, где мы найдем указатели, которые будем хотеть менять...
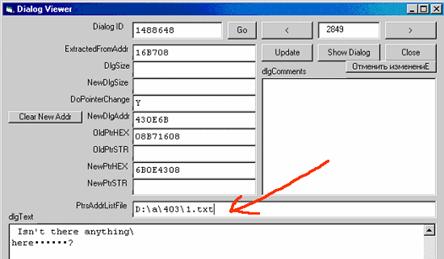
Так выглядит файл с адресами указателей:
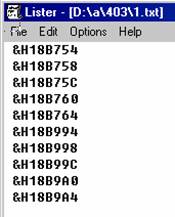
если не писать &H, значит адреса указаны в десятичном виде.
Мы в гляделке диалогов в поле PtrsAddrListFile указываем имя этого файла.
Не забываем сохранить файл диалогов...
Всё... При исправлении поинтеров будут исправлены только те поинтеры, которые мы найдем по перечисленным в спец. файле адресам, остальные четырех-байтовые последовательности (похожие на поинтеры) будут нетронуты.
Этот способ требует довольно большой ручной работы и сначала лучше постараться использовать метод номер два. (Может, со временем, я и еще что придумаю...)
Вариант 2
Который годится совсем не всегда, но позволяет избежать ручного разглядывания указателей и их адресов.
Вот еще один метод, позволяющий отсечь "похожие" на поинтеры последовательности, он тоже не идеален, и не годится для всех случаев. Дело вот в чем - процессор у GBA 32битный и адресация в роме такая же, и как правило (похоже есть и исключения) адреса указателей (не то место в роме куда они смотрят, а именно те места где лежат сами указатели) выравнены по модулю 4 (может 2 ?). Хотя я подозреваю, что это не ограничение железа, а просто Си'шным компиляторам нравится так делать. То есть если наложить дополнительное условие исправлялке поинтеров покеперевода, типа "ты не только найди определенные 4 байта, но и адрес того места, где найдены эти самые 4 байта, должен быть кратен 4-м, только тогда считай, что ты нашла поинтер"...тогда удается очень сильно сузить вероятность ошибочных исправлений... Правда в некоторых случаях, это приведет к тому, что нужный поинтер вообще не будет найден, поэтому тут уже приходится разбираться отдельно в каждом конкретном случае...
Нужно обращать внимание на количество сделанных изменений поинтеров при вставке диалогов в ром. Большие числа исправлений и нули должны тебя насторожить... к сожалению, что делать в этом настороженном состоянии я пока не придумал... как минимум, надо проверить чему равен параметр MOD4 (или CheckByMod4 в пакетном интерфейсе) см. картинки ниже...
Есть сильное подозрения, что выравненность адресов указателей характерна для "словарей", таких как списки предметов и т.п. Хочу еще раз обратить твое внимание, что такая проверка делается в тот момент, когда программа вставляет конкретный диалог в некое (ранее и отдельно! посчитанное) место в роме. С того времени, когда я начал писать эту пояснилку, прошло некоторое время, программа обновилась, и появилась спец функция заказанная Хаосом, которая за одно нажатие и высчитывает новые адреса вставки диалогов и возвращает тест диалогов в ром по тем самым местам, попутно исправляя старые указатели (поинтеры) на новые. Но по-прежнему можно всё делать по частям.
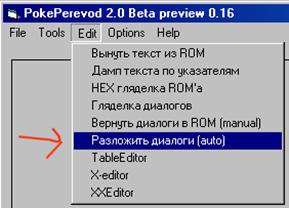
Выбрав этот пункт меню, ты увидишь примерно вот такое окошко:
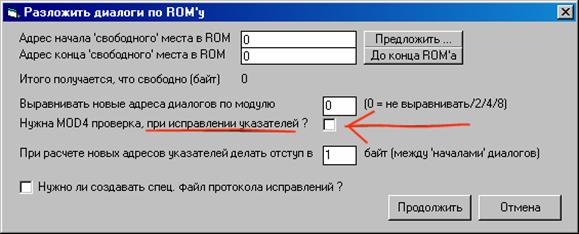
Попробуйте орби...тфу, попробуй нажать на кнопку "Предложить"... (самому мне очень понравилось).
Смысл этой кнопки такой - с конца рома программа ищет место где (кончаются 00 (нулики) или FF) и начинается нечто не пустое и этот адресок и предлагает. Тоже самое делают, скажем, "триммеры", которые укорачивают ромы для GBA, отрезая хвостовые нулики или FF'ы. Но нам этот хвостик как раз и пригодится. Естественно если "свободное" место находится в середине рома, то нажимать тут некуда и адресочки нужно вводить вручную.
Строчка "Выравнивать новые адреса диалогов по модулю" написанная, чуть выше той, что я подчеркнул, относится к тому как программа сочиняет новые адреса для вставки, и не относится к исправлению указателей.
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Вт Фев 07, 2006 2:44 pm Заголовок сообщения: |
|
|
Часто при переводе образуется несколько файлов диалогов. Причем иногда, их нельзя склеивать в один большой файл, поскольку вставлять их приходится по разному (см. выше) и может даже в разные "свободные" места в роме. Когда файлов становится больше двух, то кликать открыть то, посчитать сё, вставить так, довольно муторно... так родился "Пакетный интерфейс". Хаос, правда, просил простую склейку нескольких файлов диалогов, но мы не ищем легких путей... Пока я думаю, что получилось даже более правильное решение, в том смысле, что если переводчик (человек) разделил текст игры на несколько файлов, то он хотел, чтобы было именно раздельно и нечего тут склеивать, пусть будет раздельно, мы и так схаваем...
далее приводится пример файла, имя которого пишется в командной строке при старте Покеперевода2
скажем c:\>pokeper2.exe batch.txt
приводится он потому, что большая его часть является объяснением различных параметров...
| Код: |
'Если первый символ в строке равен "'" (аппостроф),
'то такая строка является коментарием.
'
'Регистр инструкций и параметров не важен.
'Инструкция batch интерфейсу отделяется от
'параметра знаком "=" (равно)
' ------------------------------------
' инструкции могуть быть следующими...
' ------------------------------------
'LoadRom=имя_файла
'LoadTable=имя_файла
'LoadDialogs=имя_файла
'
'SaveDialogs=имя_файла !!!файл будет перезаписан!!!
'
' эта инструкция сохраняет диалоги указанный файл,
' нужна для того, чтобы понять куда же в этот раз
' были сдвинуты эти конкретные диалоги...
' т.е. эта инструкция больше для отладки вставки
'
'
'FreeSpaceStartAddr=адрес начала свободного места в ROM'e
'FreeSpaceEndAddr=адрес конца свободного места в ROM'e
' эти два параметра устанавливают область в роме
' куда программа может перемещать диалоги, когда
' пересчитывает новые адреса вставки.
' После пересчета адресов адрес начала "пустого" места
' автоматически "подвигается", таким образом
' при пакетной вставке диалоги не накроют друг друга...
'
'
'AddressAlignBy=число может быть 0,2,4,8 (0=выключено)
'
' параметер AddressAlignBy используется при
' расчете новых аресов для вставки диалогов,
' смысл его следующий - надо ли выравнивать новый
' (сочиняемый программой) адрес начала диалога
' по модулю 0,2,4,8
'
'CheckByMod4=0 или 1 (1=true,0=false)
'
' параметер CheckByMod4 используется при исправлении указателей
' (поинтеров) и может быть равен ДА или НЕТ (1 или 0)
' смысл его такой - когда мы НАШЛИ в роме 4 байта, которые
' могут быть поинтером, то их АДРЕС проверяется по
' модулю 4 (кратен 4) и только если он кратен, только
' тогда происходит изменение этих 4 байт на новые 4 байта
' представляющие собой новый поинтер.
' Поскольку совсем не всегда такой трюк позволяет отсечь
' "левые" поинтеры, а наоборот приводит к тому, что
' вообще не находится удовлетворяющего таким критериям
' указателя, то эту фичу можно выключить...
'
'
'CalcNewPointers параметры не нужны
'
'эта инструкция пересчитывает адреса вставки и указатели
'для тех диалогов, где не указан адрес адрес вставки в ROM
'если адрес указан, то такой диалог игнорируется...
'
'
'ReturnDialgs2ROM параметры не нужны
'
'тут всё понятно из названия, эта
'инструкция возвращает диалоги в ром.
'
'SaveROM=имя_файла !!!файл будет перезаписан!!!
'
'SaveLog=имя_файла !!!файл будет перезаписан!!!
'
'содержимое окна протокола будет сохранено в указанный файл
'
'
'Stop параметры не нужны
' эта инструкция останавливает выполнение
' последующих команд из пакетного файла
'
'Fin параметры не нужны
' завершить ПП2 (закончить работу приложения)
'
'SkipUnknownTRChars=0 или 1 (1=true,0=false)
' учитывать ли длинну не опознанных по таблице символов
' при расчете длинны диалога во время пересчета новых
' адресов для вставки. (лучше пусть всегда будет=0)
' то есть НЕ игнорировать, а учитывать...
'
'DialogsAutoGapBytes=число
' при расчете новых адресов для вставки диалогов
' мы будем делать "промежуток" между концом одного диалога
' и началом следующего в столько-то байт. Этот "промежуток"
' будет содержать, то, что лежало в роме на том самом месте
' обычно это 00h или FFh...
'
'ExtendedLogs=0 или 1 (1=true,0=false)
' показывать ли расширенные логи или нет
'
'CreateInsertionLogs=0 или 1 (1=true,0=false)
' если ДА, то для каждого файла диалогов будет
' создаваться файл, где будут перечислены изменения
' поинтеров, сделанные программой, при вставке текста
' диалогов в ром
'
'Dolog=некая строка
' в окно протокола (Log) напечатается, всё, что
' написано после знака равно
'
'LoadIPS=имя_файла
'загружает из указанного файла IPS
'
'ApplyIPStoROM
'применить изменения описанные в IPS к загруженному ROM файлу
'
'IgnoreROMZone=адрес_начала,адрес_конца
'установить специальные неприкосновенные зоны, куда НЕ будут
'укладываться диалоги
'эти зоны влияют ТОЛЬКО на расчет новых адресов для вставки диалогов
'таких зон может быть определено сколько угодно,
'...в разумных приделах :-)
'пример:
'IgnoreROMZone=&H6C0000,&H6C0100
'
'
'
' ------------------------------------
' имя_файла - должно содержать ПОЛНЫЙ путь к файлу, скажем d:\a\123.rom
'
' адрес может быть написан в dec или hex виде,
' для hex написания, в начале нужно написать &H...
'
'
LoadRom=D:\Gb\hamtaro\trans\0947 - Hamtaro - Ham-Ham Heartbreak (RS).gba
LoadTable=D:\Gb\hamtaro\trans\hamtaroHex.tbl
FreeSpaceStartAddr=&H6CC540
FreeSpaceEndAddr=8388608
Dolog=так писать можно всё, что душе угодно...
AddressAlignBy=0
CheckByMod4=1
DialogsAutoGapBytes=2
ExtendedLogs=0
LoadDialogs=D:\Gb\hamtaro\trans\ready\ham-wards.rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\ham-wards2-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\ham-words-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\locations-rus.txt
CalcNewPointers
ReturnDialgs2ROM
CheckByMod4=0
LoadDialogs=D:\Gb\hamtaro\trans\ready\intro_part1-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\misc-texts1-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\sunny-peak1-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\sunny-peak2-rus.txt
CalcNewPointers
ReturnDialgs2ROM
'SaveDialogs=D:\Gb\hamtaro\trans\ready\sunny-peak2-rus.tmp
LoadDialogs=D:\Gb\hamtaro\trans\ready\sunny-peak3-rus.txt
CalcNewPointers
ReturnDialgs2ROM
LoadDialogs=D:\Gb\hamtaro\trans\ready\stones-rus.txt
CalcNewPointers
ReturnDialgs2ROM
SaveROM=D:\Gb\hamtaro\trans\0947t.gba
Dolog=закончили всё вставлять ****************
'SaveLog=D:\Gb\hamtaro\trans\log.txt
'fin
|
Совсем не обязательно единожды открывать ром или единожды сохранять выходной ром со вставленным текстом, можно после вставки каждого файла диалогов записывать новый файл...
Можно даже переводить в одном "пакете" несколько игр ;)
Кроме того, есть пункт меню "Выполнить пакетный файл", это позволит свести рутинные операции, типа загрузить ROM, загрузить таблицу и пр. к минимуму…
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Чт Фев 23, 2006 8:00 pm Заголовок сообщения: |
|
|
Прошлое...
Когда я увидел редактор, написанный Хаосом, для облегчения редактирования скрипта Breath Of Fire (вынутого Покеперводом), я понял - вот оно... то, что не хватает мне для полного счастья...
Однако, после пристального вглядывания оказалось, что мне нужно немного больше. Мне нужно было "тоже самое, но с перламутровыми пуговицами", в том смысле, что мне нужна была поддержка юникода и переменная ширина символов...
Поскольку я забыл паскаль еще в институте (а дельфи не удосужился поставить/посмотреть до сих пор), то кроме поощрительных восклицаний (и намека на то, что нехило было бы добавить ширину букв и возможность ввода "других" букв, кроме кириллицы) я ничем Хаосу помочь не мог... Выход был один - написать самому...
В то время я был только в начале пути по написанию Покеперевода версии 2, тогда вопрос с редактором скриптов стоял не очень актуально и был отложен до появления этих самых скриптов, в юникоде и все такое...
Примерно год назад...
Вот настал тот час, когда я могу вынимать (и вставлять) скрипты хоть с юникодом хоть без... Настало время подумать о том, как их редактировать...
Для начала, я написал программу типа "все в одном", которая по сути, была просто (Proof of concept) подтверждением для меня, что именно так возможно реализовать то, что я задумал. Выглядело это чудо примерно так:
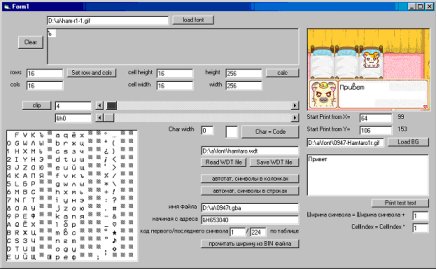
Пользоваться этим не было никакой возможности, это просто набор подпрограмм, на котором я научился выводить картинки на экран... Нужно брать и переписывать все с чистого листа...
По ходу дела я решил, как вчерне будет выглядеть мэппинг шрифта, который многозначительно назвал Font Description Table (FDT), то есть это нечто описывающее каким образом программа будет понимать, когда какую "букву" (картинку) выводить на воображаемый игровой экран. Почему я пишу слово "буква" в кавычках скоро станет понятно...
В играх (особенно в тех, где много текста ) часто используются шрифты с разной шириной букв, что усложняет процесс перевода, поскольку приходится вставлять текст "на глазок", а потом запуская игру в эмуляторе, смотреть как печатается текст (в смысле - красиво или нет), влезает ли он в отведенное окошко и не вылезают ли слова за края экрана, поскольку далеко не все игры заботятся об автопереносе текста на следующую строку…
Решение задачи осложняется тем, что в вынутом из игры скрипте часто бывают "укодированные" последовательности ("<$xx>"), которые не отображаются на экране, но влияют на то, как игра выводит текст… поэтому использование обычного редактора текста не годится… он просто не будет знать, что "<$FA>" это лишь ОДИН символ, а скажем "{-+" – это имя героя, на которое в игре (на пример) отводится всегда 60 точек или скажем 8 знако-позиций, соответственно обычный текстовый редактор, даже умея форматировать текст и предоставляя WYSIWYG (What You See Is What You Get) для печати на принтере, не даст нам представления о том, как наш скрипт будет выглядеть в игре, после вставки…
Поскольку ПП2 не встроен в эмулятор и наоборот, то делать возможность просмотра вставляемого в игру текста скрипта я решил совершенно отдельно и без привязки к конкретной приставке, размерам шрифтов, разрешениям экрана и пр….
Т.е. Идея такая – имеется набор картинок! (как бы "тайлов"), каждая представляет собой "букву" (или слово!). Скрипт, по сути, является "картой тайлов" (не нравится мне эта "карта"…), т.е. вместо кода каждого символа из скрипта игра "печатает" на экране картинку или обрабатывает эти коды как-то по особенному, не суть важно…
В ПП2 имеется свой "парсер" игрового скрипта, который занимается тем-же, чем игра – выводит вместо кодов букв, соответствующие им картинки, причем ПП, имея в своем распоряжении таблицу, знает, что некоторые строчки в скрипте, являются единичным символом, а некоторые одиночные буковки могут оказаться в игре целыми "словами"…
Что такое FDT:
Как-же объяснить покепереводу, что есть что? …
…ЧТО в таблице, КАК выводится на экран игры, для этого я придумал - FDT
FDT – это font description table - это файл, в котором мы ставим в соответствие между символами из ТАБЛИЦЫ и КАРТИНКАМИ…
!!! из таблицы мы задействуем ПРАВУЮ часть, т.е. обычные писюковые буковки, а не те коды, в которые превратится наш скрипт после перекодировки…
нужна эта фигня для того, чтобы можно было отображать текст в играх, где шрифт не моноширинный, т.е. когда ширина скажем буквы "M" больше чем ширина буквы "l" ("л" )
[повторюсь, текстом из другой пояснилки]
Так вот, смысл файла FDT следующий - там мы описываем какому символу(строке) соответствует какая картинка, и какая ширина этой картинки (не ширина для вывода картинки на экран, а ширина, которая определяет где окажется воображаемый курсор перед выводом следующей картинки). Дополнительно к этому, программе нужно знать, насколько точек вниз (и вверх) нужно перемещаться когда нужно выводить "с новой строки" - высота буквы. Стоит еще раз сказать - это НЕ ТА высота, которая записана где-то внутри GIF'а, BMP или JPG,а это столько точек нужно прибавить к координате Y, чтобы сместить курсор вниз на одну строку... назвал я ее FontWidthFontHeight (надеюсь теперь понятнее). Далее моментально выяснилось, что и этого мало... мне понадобилась картинка, которую мы будем выводить, в случае если программа не поняла что выводить на экран... я решил назвать это UnknownMappingChar. Следующий вопрос встал сам собой как отличать где имя файла с картинкой, где ширина, а где собственно символ, который мы сравниваем с отрезаемыми от скрипта (перевода) байтами. Причем поскольку формат таблицы в Покепереводе версии 2 допускает ЛЮБУЮ строку (комбинацию символов), а не только одиночные символы в правой части таблицы перекодировки (.tbl), то пришлось прилично поломать голову... чтобы это было удобно, как с программной точки зрения, так и с позиции человека набивающего FDT в notepad. Вот к такому виду FDT я пришел:
1. каждая строка (с точки зрения Notepad) описывает отдельный символ ("букву")
2. любая строка в которой НЕТ знака равно ("=") считается комментарием и игнорируется.
3. если после знака "равно" написано "FontWidthFontHeight", то взяв то, что после запятой (но перед "равно") мы узнаем высоту буковок
4. если после знака "равно" написано "UnknownMappingChar", то так мы узнаем имя картинки, которая будет показана вместо неопознанных буковок ширина ее, тоже учитывается (имеет половой смысл )
Формат файла простой:
Ширина_буквы_в_точках+запятая+название_картинки_gif/bmp/jpg+знак_равно+символ_в_win_кодировке
[другими словами]
<ширина буквы в точках>+<запятая>+<[путь]имя картинки>+<знак "равно">+<строка из ПРАВОЙ! части таблицы>
То есть в общем случае получается так - в FDT три параметра, причем два параметра отделены от третьего символом равно ("="), а первые два отделены друг от друга символом запятой (",").
В общем, на словах, получается довольно мудрено, проще показать на примере:
-----------пусть это начало файла FDT ----------------
3,D:\a\font\char-0.bmp= <---тут пробел
6,D:\a\font\char-20.bmp=0
8,16=FontWidthFontHeight <---это ширина и высота "шрифта" по умолчанию (пока я смотрю только на высоту, но вероятно пригодится и ширина...)
3,D:\a\font\char-80.bmp=1
6,D:\a\font\char-C0.bmp=2
6,D:\a\font\char-344.bmp=3
6,D:\a\font\char-140.bmp=4
6,D:\a\font\char-180.bmp=5
3,D:\a\font\unknown.bmp=UnknownMappingChar <--- это ссылка на картинку, которую мы светим, если встречаем неопознанный символ в интерпретируемом игровом скрипте, ее ширина тоже может быть разной...
6,D:\a\font\char-1C0.bmp=6
6,D:\a\font\char-200.bmp=7
6,D:\a\font\char-240.bmp=8
6,D:\a\font\char-280.bmp=9
6,D:\a\font\char-144.bmp=A
42,d:\a\font\hamtaro-name.bmp,<$Hamtaro> <--- это длинная "буква", о которой я говорил выше, т.е. мы в качестве буквы можем написать целое слово или слог (см. что такое MTE/DTE), единственное, в ПП2 такие комбинации ОБЯЗАТЕЛЬНО нужно укодировать(encode), т.е. перед комбинацией символов нужно написать "<$" а после ">" иначе программно невозможно отличить где, отдельные символы, а где слова, закодированные в игре одним кодом... надеюсь вы меня поняли... если нет, то подождите до того волнительного момента, когда я сочиню рассказ о таблицах в ПП2...
Пописывая программу, я вел неспешную беседу с Хрониксом о том, как стоит усовершенствовать редактор строк перевода в старой версии утилиты... Он тоже пришел к мысли о сложности редактирования текста, когда текст вытянут в одну длиннющую строку, изредка содержащую разные закорючки типа "/+~" означающие коды переноса на другую строку, очистки экрана, ожидание ввода пользователя (игруна) и т.д. Так я встал перед вопросом - как мне всунуть эти игровые коды в мою FDT, да так, чтобы не переписывать парсер мэппинга и не сильно ломать то, что я уже к тому времени понаписал...
Следующий параграф читать только мазохистам и/или программистам! (что очень близко)
Так родилась следующая мысль, которая и была реализована... Программа, разбирающаяся в мэппинге поступает так - берет строку текста из файла, ищет там символ равно ("=") если он есть (найден), то строку справа до конца строки считает строкой текста, а то, что слева от символа равно (вы как, еще со мной или уже того ? ) разбирает дальше... Для этого она ищет первый символ запятой (",") и таким образом делит эту строку еще раз на две части. То, что справа от знака запятой считаем именем файла с картинкой, а то, что слева считаем шириной "буквы"... Причем я запасливый в том плане, что все разобранные значения хранятся в массиве в символьном виде(в виде строк)... Короче я понял, что ничего лучше нет как засунуть признаки "more", "scroll", "cls" и другие перед первой запятой , но после ширины буквы, поскольку бейсиковой функции VAL наплевать, что там после цифр...Хотя следует заметить, что ширина спец. Инструкций (та, что в пикселях), вообще говоря должна быть нулевой...хотя...
Для обозначения специальных последовательностей символов в скрипте (типа "more", "scroll", "cls" и др.), нужно сделать следующее: в первом параметре (там где ширина нашей "буквы" в пикселях) пишем так 0MORE,.... или 0SCROLL,... поскольку их ширина по любому должна быть нулевая, то это на мой взгляд, довольно удачная идея... ВНИМАНИЕ, вы совершенно не огранинчены ОДНИМ словом, можно писать так:
0newline-more-cls,=\
0cls_newline,=<
0scrollmorescroll,=|
0morecls,=@
То есть можно писать и сочетание признаков... При интерпретации скрипта программа ищет подстроку(например "more") в строке (например "0scrollmorescroll"), поэтому думаю дальше понятно, что из этого вытекает...Хе-хе и еще это означает, что я всегда могу придумать новые спец. инструкции...
В настоящее время есть следующие признаки:
CLS - очистка экрана (интерпретатор скрипта просто еще раз загрузит фоновую картинку)
NEWLINE - координаты воображаемого курсора будут изменены (к координате Y прибавим число вычисленное с учетом второго параметра в строке содержащей FontWidthFontHeight)
SCROLL - пока работает как MORE
MORE - высвечиваем немой вопрос и ждем нажатия эникея потом продолжаем
Само собой строк мэппинга может быть столько, сколько захочешь... можно даже повторяться ;)
Раскладка мэппинга по массиву происходит по методу "тупой-еще-тупее"! это значит никакого контроля за повторениями и т.д. Выборка (сравнение отрезанных от текста диалога букв с мэппингом) производится методом перебора и сравнения, соответственно что найдем первым, так тому и быть... Укодированные символы типа <$Некая строка> рассматриваются как одна "буква".
ОБРАТИТЕ ВНИМАНИЕ: программа работает так - если находит символ "<" и сразу за ним символ "$" то пытается найти (начиная с этой позиции в строке) символ ">", если нашли и такой символ, то все, что между "<" и ">" (включая их самих) выкусывается и ищется в таблице мэппинга... это я к тому, что можно "длинные буквы" и с пробелом писать...
Кстати, удобно назвать картинки так, чтобы они оканчивались hex кодом символа из таблицы, тогда можно удобно сделать FDT из файла таблицы...
сравните:
----------таблица----------
80=A
81=B
82=C
83=D
84=E
85=F
------------------------------
-------------Font Description Table -(мэппинг)--------
8,D:\a\crystal\char-80.bmp=A
8,D:\a\crystal\char-81.bmp=B
8,D:\a\crystal\char-82.bmp=C
8,D:\a\crystal\char-83.bmp=D
8,D:\a\crystal\char-84.bmp=E
8,D:\a\crystal\char-85.bmp=F
------------------------------
Догадливые читатели уже догадались, для остальных хочу отметить, что если у вас несколько проектов, где используются моноширинные шрифты (например 8х8 или 8х16 и ширина у всех букв одинаковая), то FDT у них будут (в принципе) одинаковые, в том смысле, что можно сделать себе FDT для шрифта 8х8 и использовать его для многих игрушек где используются шрифты 8х8... Отличия в FDT будут только в части специальных кодов (cls/more/scroll) и в этих укодированных словах...
[повторюсь, словами из еще одной пояснилки]
в дополнение к этому ШИРИНА "буквы" может быть НУЛЕВАЯ!, тогда мы ее не будем видеть на экране x-preview … но у нас появляется возможность задействовать эту часть FDT под спец. параметры (флажки)…
пока есть такие флажки:
more
newline
scroll
cls
они могут писаться все вместе или поодиночке, это не важно, я лично решил разделять их знаком подчеркивания, чтобы легче было читать… в процессе "печати" ПП2 ищет (известные ему) названия флажков в первом параметре FDT и что-то делает… т.е. ты туда дополнительно можешь писать и нечто другое, неведомое мне и покепроге… ;)
Нолик в начале строки не важен, я использую функцию VAL(), которая из строки делает число, если в строке нет цифр, она просто вернёт ноль…
Для того, чтобы ПП2 не пытался печатать "непечатные символы", тебе нужно в FDT дать им нулевую ширину… вот, так просто… ;
Однако для убирания из вывода укодированных hex последовательностей, есть более простой способ – для этого в меню опций (Х-редактор) нужно отметить пунктик "Игнорировать HEX при печати"
ОДНАКО, часто бывает так, что тебе нужно не просто игнорировать Hex'ы НО и дополнительно к этому несколько условно печатных буковок идущих сразу за хексами… это, чукча тоже предусмотрел! , в меню опций (Х-редактор) нужно выбрать пунктик "Дополнительно пропускать N символов после HEX"
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Чт Фев 23, 2006 8:17 pm Заголовок сообщения: |
|
|
Так, вроде с FTD разобрались, теперь переходим к тому, как нарезать картинок. Дело вот в чем - поскольку в моем случае "буква" это совсем не обязательно тайл, то я решил, что изображение каждой буквы будет лежать в отдельном файле...
Перед тем как мы сможем воспользоваться разрезалкой букв, нам нужна картинка со шрифтом...
Для начала открываем наш ром, непринужденным прыжком переходим к изображению шрифта (сколько дней и ночей мы его перерисовывали...)
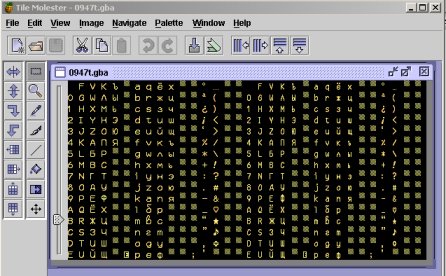
желательно, конечно подобрать палитру, так, чтобы шрифт смотрелся как в игре, но я довольно ленив для этого и просто делаю "черный по белому" примерно так:
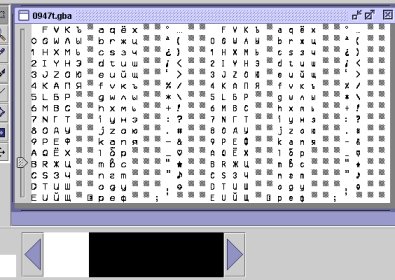
теперь мы выделяем прямоугольничек и записываем картинку в файл, подойдет формат gif/bmp/jpg.
Теперь можно запускать Покеперевод и выбирать...
Tools -->Редактор FDT
там, мы увидим примерно такую картину:
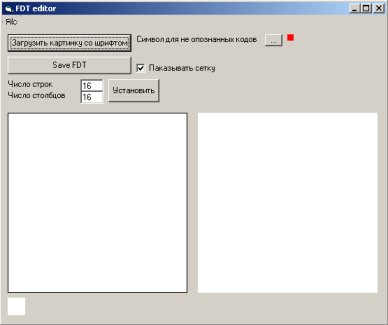
далее мы загружаем нашу картинку с изображениями букв,
выставляем сколько там у нас строк и столбцов...
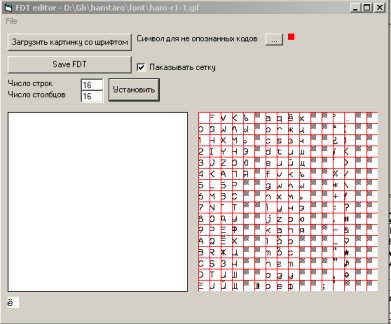
а после этого, мышкой натаскиваем нужные изображения
в левый прямоугольничек... ;)
двойным кликом (или нажатием Enter) мы выставляем
этим картинкам нужные атирибутики...
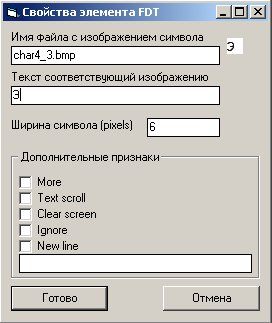
и в конце концов нажимаем Save FDT...
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Пт Фев 24, 2006 5:33 pm Заголовок сообщения: |
|
|
После создания FDT, начинается самое интересное
Загружаем таблицу(TBL) и FDT, потом в меню Edit выбираем
X-редактор, и видим нечто такое:
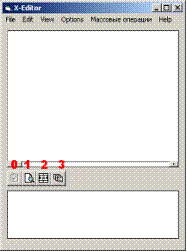
я пронумеровал кнопки, чтобы было удобнее пояснять, в принципе,
если навести на них мышкой, они сами подскажут для чего их нужно нажимать ;)
текс… теперь нам нужна картинка из игры, скажем вот такая

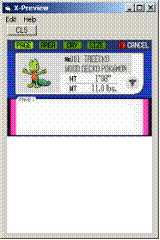
теперь нужно нажать View --> Окно X-preview, ты увидишь нечто такое
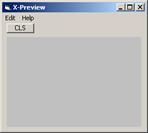
далее в этом окошке нажимаешь Edit-->Load-->Background
и выбираешь ту самую фоновую картинку…
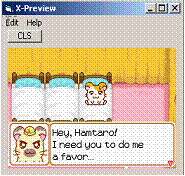
еще в том x-preview есть кратенький хелп
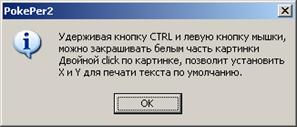
(настоятельно советую его прочитать…
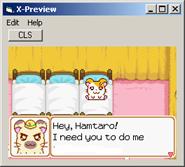
теперь нужно расчистить место для нашей писанины…
(закрасить часть игрового текста, записать и
перезагрузить фоновую картинку) получится нечто такое
произведи двойной клик мышкой в окне x-preview где-то
на белом фоне, и скажи OK
(для тонкого прицеливания в меню Options есть спец пункты… )
Обрати внимание, что нам НЕ НУЖЕН файл диалогов!!!
(точнее он не обязателен)
Однако, для некоторых подфункций НУЖНА таблица (.tbl)
Тэкс, идем дальше…
В верхнем поле редактирования просто набиваешь
(или вставляешь из клипборда) нужный тебе текст, скажем такой:
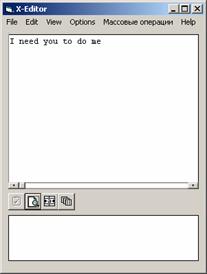
далее просто нажни кнопель  (1) (1)
ты увидишь, что текст напечатался примерно так
(в зависимости от того, как ты приметился )
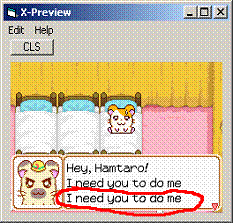
вот, как метко стреляет индеец Егор
совет на будущее – всегда сначала (если делаешь новую FDT)
проверяй на английском тексте, совпадает ли ширина строки текста…
(в смысле, правильно ли указана ширина буковок в FDT)
теперь ты можешь написать уже по русски,
и проверить влезет фраза или нет
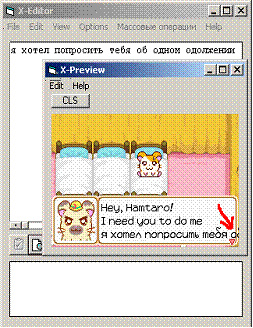
избалованные winword'ом спросят - а почему текст не перенёсся на следующую строку?
а потому, что мы не вставили символ_переноса_строки… :)
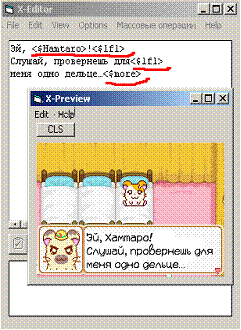
так гораздо лучше… :)
Если загрузишь диалоги, то в нижнем листбоксике, ты будешь видеть
диалоги и двойным кликом сможешь их переносить в верхнюю область
редактирования…
Не забудь принять исправления, если хочешь засунуть текст обратно
в файл диалогов, для этого нужно нажать кнопочку (0) (0)
_________________
Всех их вместе переведём!
Последний раз редактировалось: Axel (Пт Фев 24, 2006 6:19 pm), всего редактировалось 1 раз |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Пт Фев 24, 2006 6:15 pm Заголовок сообщения: |
|
|
Занимаясь форматированием покедекса, т.е. расставляя знаки
перехода на другую строку, я понял, что если делать это руками, то
это отнимает слишком много времени и нужна функция, которая сама
подравняет текст скрипта, а бы я потом лишь вносил свои коррективы…
что нам для этого понадобится –
ЧЕМ размечать (в смысле, какой последовательностью символов
обозначается в скрипте перенос строки… в нашем случае это "\", но
это может быть и длинная строка…), потом нам нужно указать
ГДЕ (в игре) проходит граница, через которую нельзя
переходить – "правая граница" (она указывается в ПИКСЕЛЯХ, ничего
ни от куда вычитать не нужно) , т.е. ты просто говоришь точку на
экране (x-preview) за которую не нужно залезать, для этого ты просто
двойно-кликаешь на картинке x-preview и смотришь координату X!,
НО отказываешься от предложенного действия…
для установки этих параметров в меню "Options" (в x-редакторе)
были дописаны соответствующие пунктики:

поке-прога (относительно) умная и сначала поищет, что у тебя
написано в FDT в качестве переноса строки, и предложит это
значение… правда если у тебя НЕСКОЛЬКО таких спец символов
(у которых во флажках написано newline), то ПП2 предложит тебе
лишь первый, но ты можешь это изменить (просто введя ручками
другое значение)
...идем дальше…
Поскольку у нас может получиться так, что отформатированный текст
вылезет за экран или это многостраничный кусок скрипта, то для
начала нужно удлинить наш "игровой" экран, для этого в x-preview
выбирай пунктик и установи, скажем 240 на 320
а потом просто растяни окно x-preview вниз…
Для того, чтобы отформатировать текст скрипта, навставляв
туда "переносов строк" нужно нажать кнопку, отмеченную как  (2), (2),
можно нажать "горячую" кнопку "серая 5" на дополнительной
(цифровой) клавиатуре…)
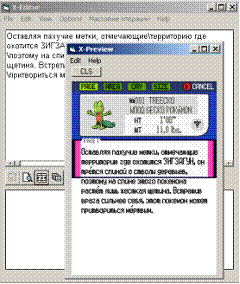
…моментально становится видно, что я не помещаюсь в три строки на двух экранах… (всего должно быть 6 строк)
далее я начинаю уже руками расставлять переносы (в словах),
двигать переносы строк… вот тут очень удобно нажать CTRL+H
(найти и заменить), причем в эта функция находит и заменяет
НАЧИНАЯ с того места, где у меня стоит курсор…
! обрати внимания автопереносилка НЕ трогает уже расставленные
знаки переноса строк, а лишь добавляет новые, поэтому ей можно
(и нужно) пользоваться несколько раз…
в итоге я получаю нечто такое
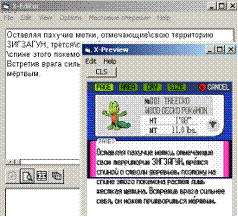
теперь осталось заменить каждый N-ный "перенос строки" на "новая станица"
и эта глава покедекса готова… для этого задумана кнопка  (3) (3)
эта функция ЗАМЕНИТ некоторые знаки переноса строки на знаки,
обозначающие "новая станица"… но ей нужно знать, сколько строк
у меня на странице… идем в меню options (в x-редакторе) или жмем
указанную кнопку (3), если нужные параметры еще не установлены,
тебя спросят…
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
Axel
Советник
Зарегистрирован: 14.11.2003
Сообщения: 680
|
| Добавлено: Вс Фев 26, 2006 12:15 pm Заголовок сообщения: |
|
|
ВОПРОС:
Тема такая - мне надо в этом твоем новом редакторе,
чтобы в таблице однобайтового типа были "двухбайтовые коды", то есть вот, например:
>
> 0609=Герой
> 2A=A
> 2B=B
> 2C=C
> 2D=D
ОТВЕТ: ЕСЛИ у тебя нет кода 06, то ты можешь прямо так и написать:
-------------cut here
TrTableType=SBCS2
0609=<$Герой>
2A=A
2B=B
2C=C
2D=D
-------------cut here
обрати внимание на то КАК я написал слово Герой, все, что длиннее чем 1 символ
нужно укодировать в "<$" и ">"
строка TrTableType=SBCS2 говорит программе о том, что в случае
если однобайтового совпадения НЕ найдено, то нужно отрезать от
рома следующий байтик и попробовать поискать двухбайтовое
сочетание...
ты можешь себя не ограничивать одним символом после знака равно,
а тоже самое написать так:
09=<$new_line><$VBCRLF>
03=<$scroll><$VBCRLF>
...
!!! ЛУЧШЕ -НЕ- писать так:
09=<$VBCRLF>
иначе будут непонятки при вставлении скрипта...
лучше писать некую строку ОБЯЗАТЕЛЬНО "укодированную" и сразу за ней
<$VBCRLF>...
!!! если у тебя УЖЕ описан символ с кодом 06, то ты так
сделать НЕ можешь, (т.е. ты не должен указывать тип таблицы SBCS2,
потому как это все равно не сыграет...)
потому, что при вынимании текста уже найдется однобайтовый
код (в таблице), поэтому в таком случае ты должен сделать
следующее:
скажем у тебя уже описан код 06 и равен он символу "&" а кода 09,
скажем нету...
(ты можешь его описать просто как "<$09>" или НЕ описывать,
но тогда не забудь в меню опций сказать "укодировать неописанные
в таблице коды", хотя я советую его описать...)
-------------cut here
06=&
09=<$09>
2A=A
2B=B
2C=C
2D=D
<$POSTPROCESSOR>&<$09>,<$Герой>
<$POSTPROCESSOR><$FF><$F6>,<$sunflower seeds>
<$POSTPROCESSOR><$FF>1<$F5>,<$sunflower seed>
<$POSTPROCESSOR><$F1>1,<$словарик>
-------------cut here
я написал еще пару сочетаний, чтобы стало немного понятее...
идея постпроцессора такая - в только-что-вынутой-строке-скрипта
поискать подстроку которая написана сразу поле слова "<$POSTPROCESSOR>"
(и отделяется запятой) и заменить эту подстроку на то, что написано сразу
после запятой...
еще один пример - кусок таблицы для К**** ---
----------------cut here
/0A
00=~
01=@
02=$
03=^
04=№
05=#
06=\
07=&
08=¤
09=<$09>
0B=<$0B>
0C={
0D=}
0E=_
0F=|
10=<
13=<$[ё]>
20=
21=!
6E=n
6F=o
70=p
71=q
72=r
73=s
74=t
75=u
76=v
77=w
78=x
79=y
7A=z
<$POSTPROCESSOR>#<$09>,<$Page>
<$POSTPROCESSOR>@~,<$Begin>
<$POSTPROCESSOR>#№,<$Next>
<$POSTPROCESSOR>^~&@,<$VBCRLF><$Soma>
<$POSTPROCESSOR>^@&$,<$VBCRLF><$Mina>
<$POSTPROCESSOR>^$&^,<$VBCRLF><$Genya>
<$POSTPROCESSOR>^$&&,<$VBCRLF><$?Genya?>
<$POSTPROCESSOR>^^&№,<$VBCRLF><$Graham>
<$POSTPROCESSOR>^^&&,<$VBCRLF><$?Graham?>
<$POSTPROCESSOR>^№&#,<$VBCRLF><$Yoko>
<$POSTPROCESSOR>^№&&,<$VBCRLF><$?Yoko?>
<$POSTPROCESSOR>^#&&,<$VBCRLF><$?jj?>
<$POSTPROCESSOR>^#&\,<$VBCRLF><$jj>
<$POSTPROCESSOR>^#&¤,<$VBCRLF><$Julius>
<$POSTPROCESSOR>^¤&№,<$VBCRLF><$2Graham2>
<$POSTPROCESSOR>^&&@,<$VBCRLF><$2Soma2>
<$POSTPROCESSOR>^\&<$09>,<$VBCRLF><$Hammer>
----------------cut here
есть еще одна хитрость - "/0A" она означает, что если при вынимании
текста встретится байт с кодом 0A, нужно "оборвать" эту последовательность
(так же как если мы встретили НЕ ПЕЧАТНЫЙ КОД...)
в общем, обрати внимание на инструкции постпроцессору, думаю ты знаешь, что на что я меняю...
самое главное, что тут НЕТ места ошибкам, типа "проглядел сочетание символов"...
и эти автозамены являются неотъемлемой частью таблицы, в смысле не потеряешь,
(или потеряешь вместе с таблицей ) что на что менял...
ПРЯМО ПЕРЕД вставкой диалогов обратно в ром я заменяю все как было,
т.е. ищу подстроку которая написана ПОСЛЕ запятой и меняю на то, что
до запятой... короче на то, что должно быть в скрипте для его правильной вставки...
да, и еще одно - "<$VBCRLF>" эта подстрока автоматом заменяется на перевод строки
(с точки зрения notepad), так диалоги намного легче читать... ;)
ВОПРОС:
> Спасибо, идея с подпроцессором именно то, что мне нужно.
> Тип таблицы, как я понимаю, должен быть SBCS2.
ОТВЕТ:
НЕТ! тип таблицы делай SBCS (или не задавай совсем, тогда по умолчанию будет
SBCS)...
ВОПРОС:
> я не понимаю - В файле текст.txt есть вынутая строка
> и в ней почему-то строка не разбита на части, а идет сплошняком,
> хотя символ 00 у меня
> в таблице таблица.tbl не описан. Чего я не понял?
ОТВЕТ:
да, ты не понял просто символ_конца_строки теперь это ОБЫЧНЫЙ символ,
такой же как остальные, просто его нужно писать по особенному...
ввиду совместимости со стандартными thingy таблицами...
описывается этот символ строкой "<$VBCRLF>" (без кавычек и ОБЯЗАТЕЛЬНО
ЗАГЛАВНЫМИ БУКВАМИ!),
при чтении таблицы я его заменяю на "нормальный" конец строки... hex(0D0A)
т.е. еще раз, там где ты хочешь иметь "преренос строки" (notepad'овый), пиши
<$VBCRLF>
в пример я привел тебе таблицу из К****...
вот смотри:
<$POSTPROCESSOR>^~&@,<$VBCRLF><$Soma>
эта строка превратится при вынимании скрипта в:
"перенос_строки"
<$Soma>
ВОПРОС:
> А еще я так и не понял, зачем нужны вот эти §,¶ в начале и конце каждой строчки скрипта?
ОТВЕТ:
Посмотри в pokeper2.ini - первый символ (+ переносы строк!) отделяет один диалог от другого,
второй (+ переносы строк!) отделяет параметры диалога друг от друга (типа откуда вынули, куда вставлять...)
ты можешь в INI файле описать как угодно
чем ты разделяешь диалоги и их атрибуты
хоть так:
DialogDelimiterStr=<$VBCRLF>---- конец диалога ----<$VBCRLF>
DialogAttrDelimStr=<$VBCRLF>---- начало диалога ----<$VBCRLF>
что (наверное) будет наглядее...
!!! только не забудь, что перед "началом диалога" есть еще ОДНА строка с
атрибутами этого диалога
список параметров диалога тоже описан в .ini (лучше пока его сам не меняй... хотя можно )
ВОПРОС:
> И расскажи как можно подробнее о вставке скрипта обратно в ром.
> Почему программа вынимает текст в виде диалогов (если я правильно понял), а не просто строк;
> где делается пересчет поинтеров; - в твоем новом редакторе так много всего, что я просто запутался...
ОТВЕТ:
1. у каждого диалога есть параметр, описывающий куда его совать, он совсем не обязательно
совпадает с местом, откуда его вынимали...
2. вставляются ТОЛЬКО те диалоги у которых УСТАНОВЛЕН параметр NewDlgAddr,
ты можешь нажать кнопку и присвоить NewDlgAddr=ExtractedFromAddr (вставлять по старым адресам),
а можешь расчитать новые! см. надписи на кнопках... ;)
3. ты можешь расчитать и поинтеры (или написать руками! если ты хочешь и знаешь что они именно такие...)
параметр "исправлять указатели" (в гляделке диалогов) разрешает (или нет) после вставки диалога
заметить указатель для конкретного диалога...
ВОПРОС:
> Я так понял, что эти диалоги и являются полуавтоматической системой того, что раньше было полностью автоматически.
ОТВЕТ:
раньше было хуже... :)
короче, если ты загрузишь диалоги, откроешь "гляделку диалогов" и нажмешь кнопку
<Присвоить NewDlgAddr = ExtractedFromAddr (кладем по старым адресам)!для ВСЕХ диалогов!>
то будет как раньше... ;)
...я просто хотел тебе напомнить, что в ПП2 есть ИМПОРТ и ЭКСПОРТ
"файлов перевода" сделанных версией ПП1...
так, что ты можешь прыгать туда-сюда как тебе захочется...
НО!, ПП1 НЕ знает об укодированных символах ("<$....>")
поэтому длинна строки будет не совсем верная...
Имей ввиду еще одну фишку - ПП1 считает начало РОМа с ЕДИНИЦЫ,
а ПП2 с НОЛЯ! (процедура импорта это учитывает, но если ты
будешь это делать руками не забудь вычесть 1 из адреса...)
в файле диалогов (ПП2) первый по счету параметер (в ПП1 это адрес ОТКУДА вынули)
просто некий идентификатор, он больше НИКАК не используется!, а вот
второй параметер (написанный в hex), это адрес откуда вынимали...
при импорте файла перевода я беру это число(адрес из ПП1) вычитаю 1 и перевожу в hex...всё.
(идентификатор диалога (ПП2) всегда равен адресу из строки перевода (ПП1) )
ВОПРОС:
> Вроде дошла природа глюка - PP2, при вытаскивании текста, вместо того,
> чтобы оборвать строку, там, где наткнется на 00, пишет вместо него тот
> символ, который стоит следом, то есть дублирует...
ОТВЕТ:
код "принудительного обрыва последовательности" в таблице описывается НЕ ТАК,
как все остальные коды...
в строке таблицы ПЕРВЫМ символом должен быть "/"а потом БЕЗ знака равно код
байта...
пример (из Кастельвании)
-------начало таблицы для кастельвании...
/0A <---------вот он, код принудительного обрыва!
00=~
01=@
02=$
03=^
ВОПРОС:
> Значит я перевел для проверки несколько диалогов
> (каждый из который по сути является одной
> строкой - неудобно стало с этими дополнительными символами-отделителями
> параметров и строк - для глаза неудобно) и вставил в ром, указав, как
> начало для вставки, адрес первой
> строки, а концом конец рома - и вроде бы всё посчиталось - с чистой
> совестью всё сохраняю
> и возвращаю обратно в ром - запускаю игру - первая строка выводится
> нормально, я даже немного успокаиваюсь - но как только первая строка
> должна прекратить выводиться, тут же начинает
> выводиться следующая строка, а соединяет их какая-то произвольная буква...
> лезу в Hex, смотрю...
> там, где раньше PP1 ставил 00 как разделители между строками
> (а может я так только думаю, я же на пустое место текст клал),
> теперь стоят какие-то английские буквы - короче я так полагаю, что
> должен сам ставить символ конца строки, вот только ПП2 пропускает еще один
> символ - а это место и со временем его набежит порядочно - нельзя ли с
> этим чего-нить сделать?
ОТВЕТ:
в гляделке диалогов есть кнопка, которая добавляет В КОНЕЦ КАЖДОГО диалога некую
строку...
ты скажи ему добавить скажем <$00> , а при расчете новых адресов (и
указателей (поинтеров))
скажи выравнивать по модулю 1 !
ВОПРОС:
>вставил в ром, указав, как начало для вставки, адрес первой строки
ОТВЕТ:
ТАК ДЕЛАТЬ НЕЛЬЗЯ !!! ты должен указывать начало и конец ПУСТОГО МЕСТА в РОМе!!!
иначе ты своим скриптом накроешь нужные данные игры...
(что видимо и произошло)
ВОПРОС:
> Сейчас у меня просто непонимание - возвращая текст обратно в ром
> (разумеется с изменением поинтеров),
> ПП2 мне сказал, что "меняли поинтер 08B61608 на 42AB1608 сделано 153
> изменений", хотя все остальные только по одному разу. Я не понял,
> каких изменений? Это он в роме столько четырехбайтовых значений
> похожих на нужных поинтер нашел? И чтобы не ошибиться, исправил все???
> Обьясни, пожалуйста, по-человечески.
ОТВЕТ:
да это именно столько четырех-байтовых последовательностей он (ПП2) исправил,
посчитав их указателями...
это означает, что вероятно это НЕ поинтер, в том смысле, что ты(он ) не
угадал "начало диалога"...
такое число указателей может быть только на "словарь"... и то врядли...
> Не совсем понял твою мысль... Я вообще редко понимаю сразу твои идеи
> Но мне почему-то в голову пришла такая идея - пусть при вставке диалогов
> в ром создается лог-файл "имяфайладиалога.log" в котором будут перечислены все поинтеры
> (или адреса - не знаю - но чтобы можно было все 513 поинтеров (как в моем случае)
> отсортировать и чтобы ПП2 понял, что я имею ввиду)- ну скажем:
Да будет так ;)
Моя терминология:
-----------------
поинтер - это 4 байта у которых "правый" всегда hex(0
адрес поинтера - это место в РОМе, где я могу найти поинтер
куда смотрит поинтер - это адрес в РОМе, который я ВЫЧИСЛЯЮ на основании поинтера (тех 4-х байт)
буду писать лог следующего вида:
------- номер диалога (DialogID) ---...тут может еще чего напишу----
адрес поинтера в роме (где исправляли)
адрес поинтера в роме (где исправляли)
адрес поинтера в роме (где исправляли)
адрес поинтера в роме (где исправляли)
------- номер диалога (DialogID) ---...тут может еще чего напишу----
адрес поинтера в роме (где исправляли)
адрес поинтера в роме (где исправляли)
------- номер диалога (DialogID) ---...тут может еще чего напишу----
... и так далее ...
тогда не мудрствуя лукаво, можно будет COPY/PASTE
эти адреса поинтеров в тот самый файл (1.txt из пояснилки)
но естественно можно будет не все адреса копировать,
а только те, что нам нужны ("правильные")...
короче, сделаю, это не проблема вааще... ;)
> Правда в моей ситуации поинтер будет один и тот же, но адреса то разные,
> а потому и лучше - насколько я понимаю, поинтеры лежат рядом, а потому по
> другим поинтерам будет легко вычислить, какой настоящий
именно так!
> для меня не существует проблемы нахождения начала строки - всё и без того очень очевидно).
я бы так уверенно этого не говорил...
в пояснилке, я намеренно привел тот кусок скрипта (дампа по указателям)
там есть диалоги, где с той таблицей, что ты посылал некоторые "начала" диалогов
не правильные (т.е. не совпадают с теми местами куда смотрят поинтеры)...
но в принципе, ты прав...
вобщем и целом ОЧЕНЬ внимательно относись к тем диалогам, для которых НЕ находятся
поинтеры т.е. при вставке диалогов с исправлением указателей тебе говорят
"изменяли поинтер ... на ... сделано НОЛЬ изменений" - это дожно тебя насторожить!,
вполне вероятно, что "правильное" начало диалога не там (+/- несколько байт)...
> А потом почистив этот лог-файл, прописать его при вставке
> (мне вот интересно, я не твою ли идею просто немного извратил
> или просто совпадение) текста и ПП2, смотря в лог-файл и видя
> истинный адрес поинтера (который ему надо исправить) будет исправлять
> его именно там, а ложные поинтеры игнорировать.
да, ты правильно понял идею...
просто "сканировать лог" довольно муторно (и долго),
поэтому операция будет по-шаговая...
1. исправляем все подряд и пишем лог
2. ЕСЛИ что не так, смотрим в лог, находим там место про конкретный диалог,
выкусываем оттуда адреса поинтеров и создаем файл...
3. указываем для конкретного диалога в поле PtrsAddrListFile того созданного файла...
4. постепенно сокращаем число адресов, там написанных, до получения желаемых результатов...
> > раз десять прочитал, пока понял
> > это файл с адресами "правильных" поинтеров для ЭТОГО (конкретного) диалога
> > (естественно он свой у каждого диалога... ведь и поинтеры свои )
>
> Погоди. Но ведь на каждый конкретный диалог есть только один правильный
> конкретный поинтер и соответственно один правильный конкретный адрес этого
> поинтера.
Не совсем так, я бы сказал, что ЧАЩЕ именно так, на один диалог
есть один указатель (на его начало), НО! представь себе, такую картину -
у тебя (в игре) есть, скажем пещера и в ней 1000 сундуков, герой
может открыть сундук и узнать, что "Этот сундук пустой...",
ты, как разработчик этой игры наверняка решишь, что проще
сделать ОДНУ СТРОКОВУЮ ПЕРЕМЕННУЮ с текстом = "Этот сундук пустой...",
а потом для всех пустых сундуков сделать ссылку на тот текст
(в той переменной), нежели для всей 1000чи пустых сундуков
написать 1000у раз фразу "Этот сундук пустой...".
То есть, нужно смотреть по смыслу фразы, может быть так, чтобы такая
фраза встречалась более одного раза или нет...
!!! НЕ забывай, что для тех диалогов для которых сделано НОЛЬ
исправлений поинтеров нужно перепроверить правильно ли мы
угадали "начало" этого диалога и не является ли он продолжением
вышележащего... !!!
я исправлю прогу, чтобы при ВЫключенных расширенных логах печаталась информация только про НОЛЬ исправлений поинтеров И
если было сделано БОЛЕЕ одной замены...
Ну, что же... вот и настало событие, которое могло произойти 2 года назад, но по многим причинам было отложено...
Отправляйтесь в самый первый пост этой темы, там вас ждёт сюрприз...
_________________
Всех их вместе переведём! |
|
| Вернуться к началу |
|
|
&ryu

Зарегистрирован: 09.10.2004
Сообщения: 259
Откуда: Город Юности
|
| Добавлено: Вс Фев 26, 2006 1:47 pm Заголовок сообщения: |
|
|
Я мечтал об этом полтора года (даже больше).
У меня нет слов...
ありがとうございます!!!
_________________
"Человек сам вершит свою судьбу..."(Ричард Рал) |
|
| Вернуться к началу |
|
|
Гость
|
| Добавлено: Вс Фев 26, 2006 1:51 pm Заголовок сообщения: |
|
|
| &ryu писал(а): | У меня нет слов...
ありがとうございます!!! |
...это лишь средство... голову никто заменить не сможет... |
|
| Вернуться к началу |
|
|
Zubastik-не авторизован
Гость
|
| Добавлено: Вт Фев 28, 2006 2:12 pm Заголовок сообщения: |
|
|
| Хехехе... осталось написать книгу ПокетПеревод для чайников и можно смело вставать на ступень, рядом с ВИндой +)))) |
|
| Вернуться к началу |
|
|
|
|
Вы не можете начинать темы
Вы можете отвечать на сообщения
Вы не можете редактировать свои сообщения
Вы не можете удалять свои сообщения
Вы не можете голосовать в опросах
|
Powered by phpBB © 2001, 2005 phpBB Group
|

